04.03.2026
OpenGov Lab data as a source for training GPT-NL
The OpenGov Lab's WooZM (former WooGLe) dataset was used as a source for training GPT-NL, a large language model focused on Dutch language. The Woogle dataset, which contains millions of documents and metadata from the Dutch government, provided a rich and diverse source of text for training GPT-NL.
 There we are, at the bottom right corner!
There we are, at the bottom right corner!
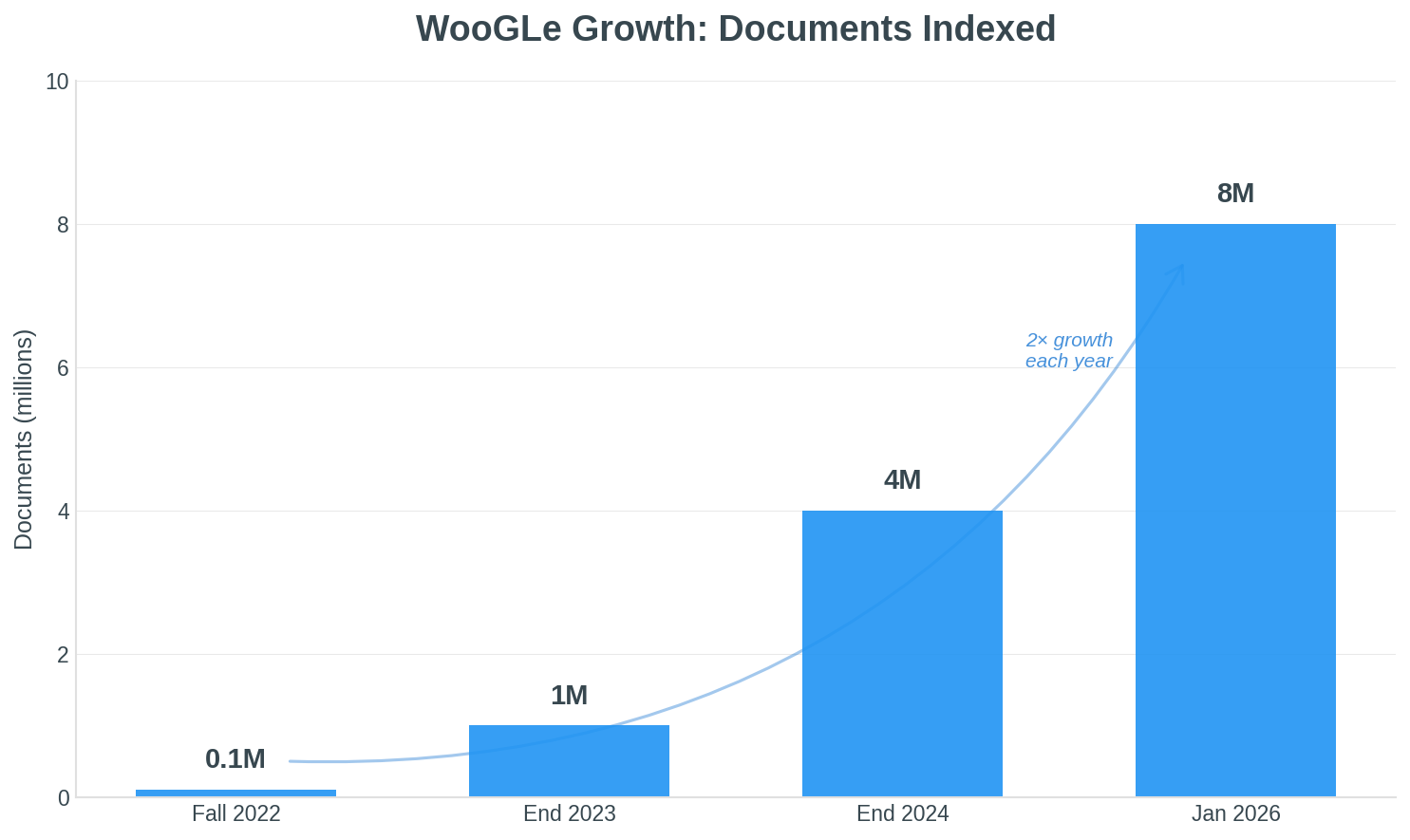 WooGLe's document count has doubled each year since launch
WooGLe's document count has doubled each year since launch